Contents of this section
Define Files Description
Beginner Design
filePro and Non-filePro files
Data Types [edits]
Create Default Formats
Qualifiers (basic)
Description:
When defining a new filePro file, filePro will create a subdirectory in the "filePro" directory with your chosen filename. All of the screens, formats, user data, etc., for this filePro file are stored as regular system files within this named directory. Therefore, a filePro filename actually refers to a directory name.
Under Unix, the filePro filename can not exceed 14 characters in length. Under WINDOWS, the filename size can be up to 8 characters long. The WIN95/98/NT version allows up to 32 characters for filename. It is good practice to use filenames that have more than two characters.
Beginner Design
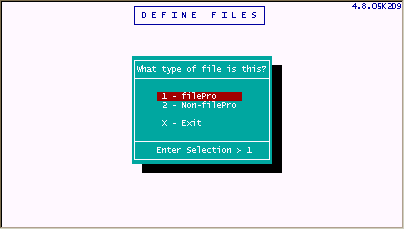
When you define a filePro file, after you pick <NEW> and enter a filename of your choice, you will see the following screen:
"filePro & Non-filePro files
filePro can work with filePro format files and flat ASCII files. The flat ASCII files or "non-filePro" files are also called "alien" files because they are not structured in the filePro format. It is normally better to use the filePro file type since it keeps track of things like "Creation Date", "Date Last Updated", and other system information that is useful in selecting and maintaining the records.
When selecting either file type, you are prompted for a creation password.

With this password, you can prevent others from changing your file structure and formats. If you are a beginner, do not use passwords. Creation passwords can always be applied later.
After the password prompt, you are presented with a "Define Files" screen as follows;
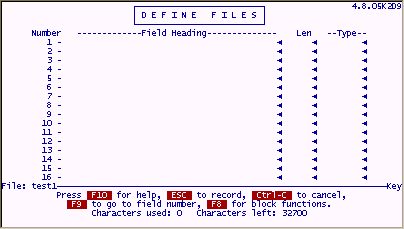
Field Heading
You simply enter a description that is meaningful for each field under "Field Heading". Although the description can be anything you want (up to 32 characters), use descriptions that are meaningful to the user.
Headings longer than 21 characters may be truncated on some screens.
Len
The Len is the maximum number of characters that the field will hold. Remember to leave space for punctuation in dates and non-integer numbers i.e. "04/21/99" is 8 characters, "99999.99" is 8 characters. Many edits (discussed later) such as "Dates", "Time", etc. have specific field length requirements. The Len is limited to a number between "0" and "999". Many programmers use a zero "0" in the "Len" column to reserve lines for spare fields but normally a number "1" through "999" would be entered as the length of a field. It is best to limit the length of the field to what you think you really need since longer fields take longer to sort and will use up unnecessary space when storing the data.
Type (Edit)
The "Type" is short for "Edit Type". This column determines the kind of information that will be allowed in the field. If the "Type" column is left blank or contains an " * ", the user will be able to enter just about anything. filePro provides pre-defined types (edits) such as; "allup" to capitalize any data input into the field; "phone" to insert parentheses and dash in a typical phone number format. You can also create "user edits" which will be discussed later.
Data Types
Data can be classified into four major groups or "Data Types" as follows;
Character: |
Any combination of ASCII characters (almost anything) |
Numeric: |
Integer numbers; numbers with decimal values or commas |
Date: |
Dates in various formats mdy; mdy/; ymd; ymd/; etc. |
Time: |
In hours & minutes - hm; or hours, minutes & seconds - hms |
IMPORTANT: If you will need to perform any math operations on a field, be sure that the field is defined as a "Numeric" data type. If you need to perform any date calculations on a field, use the "Date" data type.
Example: To make sure that a Social Security Number is always entered correctly, we can enter "SSNUM" in the "Type" column to ensure that Social Security Numbers are always entered; with the correct number of digits; as numbers; with the " - " dashes which will be automatically insert dashes, if not provided.
User Input |
Edit Results |
Description |
123121234 |
123-12-1234 |
Valid Data & dashes inserted |
123-12-1234 |
123-12-1234 |
Valid Data |
a12121234 |
SSN Invalid |
Data rejected "a" is invalid |
The "SSNUM" example is just one of many "edits" pre-defined for you in filePro. Edits are contained in tables called "Edit Dictionaries". The "GLOBAL Edits Dictionary" contains the pre-defined edits furnished by filePro to cover commonly used fields like phone, zip, state, allup, cheque, SSN etc. Click on edits to view the "GLOBAL Edits Dictionary".
User Edits
The data allowed in a field can be further constrained by creating your own filePro "User Edits". "User Edits" are maintained and associated with a specific filePro directory. Therefore, "User Edits" are unique to each filePro file unless you include the edit in the "GLOBAL Edits Dictionary".
A typical filePro file
The following is a snapshot of a filePro called "FPCUST".
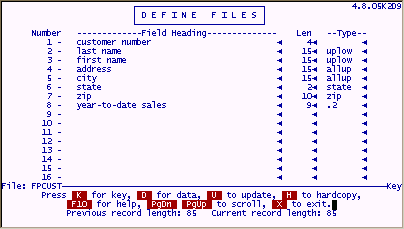
This file is a typical customer file that you might create. Notice that the field headings are self-documenting, so when the end-users access the data, they will know exactly what it is. The "Len" length of the fields are typical of what you will need to accommodate "last name" first name" etc.
The "edit types" column contains "uplow" for the name fields which will always capitalize the first letter in the name and set all other characters in the name fields to lower case unless you have purposely typed a character in caps. The "allup" edit will set the address and city fields to "all uppercase". This is a normal U.S. Postal Service requirement. The "state" edit type will ensure that only valid state abbreviations can be entered. The "zip" edit type will handle both 5 character and 10 character zip codes. The ".2" edit for "year-to-date sales" will ensure that dollar amounts will always be formatted with 2 decimal places.
Selection Options
K for Key |
Press K for the key segment. filePro data can be split between two Segments called "key" and "data". When entering "Define Files"The "key" segment is used by default. |
D for data |
Press D for data segment. Most developers no longer use the "data" segment. It is still maintained for compatibility to older versions of filePro. |
U to update |
Press U to define or change fields. |
O for Options |
Press O to select Advanced Options |
H to Hardcopy |
Press H to print a list of the fields and definition. |
PgUp PgDn |
Use to see fields below and above the edges of the screen. |
X to Exit |
Press X to record the changes. |
The "Previous record length" and "Current record length" are provided for informational purposes.
Press "U" to update
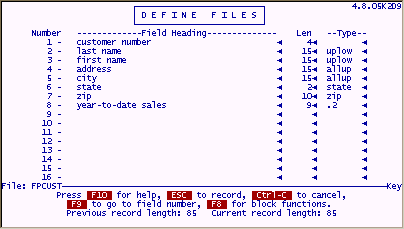
When entering Update, the selection options change at the bottom of the screen.
F10 for Help |
Retrieves system help for define files. |
ESC to record |
Saves the changes made to your file definition. (this is ESC ESC on UNIX and other systems. Refer to Terminal Guides ) |
Ctrl - C |
Cancels changes made. |
F9 to go to . |
Used with definitions with many pages to quickly go to a Specific field number. |
F8 for Block... |
Allows you to copy rows quickly. |
|
|
By pressing the "F10 for Help" key, you can retrieve the system help for each section. The following is an example of what you see for the "Type" column.
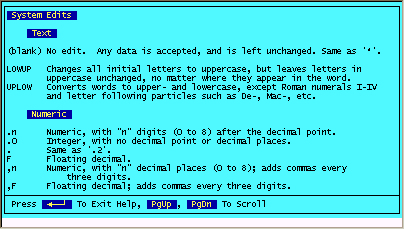
Select Options
Create Default formats
After creating / updating in "Define Files" and saving the file definition , you are presented with various options for creating default formats. When typing a "Y" for these options, defaults will be established or you will be presented with additional screens to specify the values for the defaults.
Creating a screen 0 (Y/N)
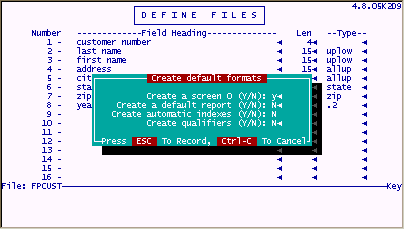
"filePro" tries to make a screen from the fields provided. Sometimes there are too many fields or the field lengths are too long. In these cases, filePro truncates the screen to whatever it can do.
Create a default report (Y/N)
The default report will be labeled "default.out" in WINDOWS or "out.default" in UNIX/LINUX systems.
Create automatic indexes (Y/N)
You can elect to create indexes at this time or create at a later point using the "Index Maintenance" option. Automatic indexes can be established for any field in the key segment. For filePro versions prior to 4.5, automatic indexes could only be built on multiple fields if the fields were concatenated (if maintained in the map next to each other). For example, in the "FPCUST" file, an automatic index could be built on "last name" and "first name" by extending the sort length to 30 characters, 15 characters for "last name" and 15 characters for "first name". With versions 4.5 and later, you can sort on multiple fields no matter where they are defined in the map.
Create qualifiers (Y/N)
Qualifiers allow you maintain multiple sets of data for a single filePro program definition. This is valuable for maintaining a separate set of data for testing your design i.e. use a qualifier name "TST" for test. Other uses include maintaining sets of data for multiple customers i.e. payroll systems for company A, company B and company C, or inventory data for more than one convenience store. As a developer, the qualifier feature is valuable for testing or troubleshooting a data problem for customers. Qualifiers allow you to maintain multiple copies of data for a single set of filePro program files. Data from a customer site could be copied with a qualified name to the same filePro directory. So when you make a change to a process, report or screen, the changes can be easily maintained since you will only have a single version or a master of your programs. The following screen will be presented by define files when you set the "Create qualifiers" option to "Y".
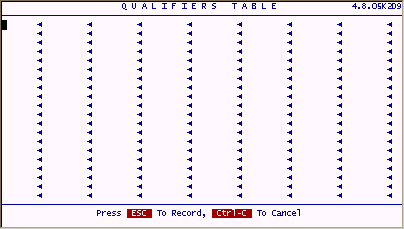
Enter the qualifier names you wish to create. After pressing ESC, the files associated with filePro data will be created in the respective filePro directory.
Example:
If you entered qualifier "TST" for test, the filePro directory would contain "keyTST", "dataTST", "indexTST.a", etc. The qualified sets of data can be accessed through processing, by using the appropriate menu flags or from the command line.
Other uses of qualified sets of data may include developing divisional accounting systems. The data for each division may be maintained in qualified data sets while the corporate-wide data may be maintained in the non-qualified data set. filePro processing allows you to easily post and retrieve data between qualified sets with the "LOOKUP" command.
Advanced Concepts - Define Files
Contents of this section
Design Considerations
Associated Fields
Non-filePro Files
Qualifiers
Design Considerations
You can very quickly design applications with filePro ranging from a simple "single" file application (rolodex) to complex relational database applications containing many filePro files (accounting system). Although it is relatively easy to go back and make changes with the "Define Files" option, it is best to give some thought to organization and logical grouping of fields in this option on your initial design. If you forget something or put something in the wrong place, it is not difficult to add or change the fields at a later time since filePro will take care of restructuring your data with ease. You dont want to be forced to re-visit a design any more than necessary, so this preliminary organization will save you time.
Associated fields
These fields are sorted and selected as a group. Whenever one member of the group is specified, all members of the group are considered. These fields can only be defined as real fields with the "Define Files" option. The following provides a sample of associated fields for "product code" and "quantity".
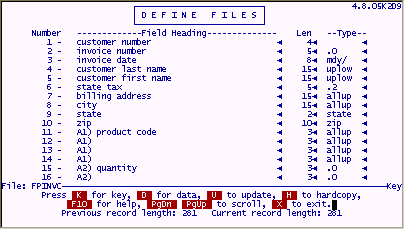
Associated fields are designated with a "letter" , a "number" followed by a close parenthesis, and then whatever description you want to give the group of fields. You can also add subfields ( the quantity fields) by starting with the same letter and advancing the number.
Example:
A1) product code A2) quantity
A1) A2)
A1) A2)
A1) A2)
In the above example, we now have two associated field groups containing four fields each.
Selecting
To demonstrate the advantage of selecting data using associated fields, refer to the following;
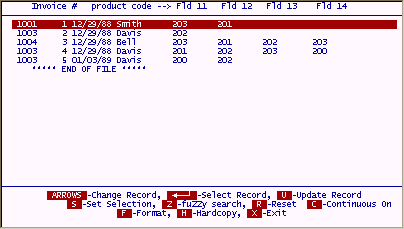
In the above screen, you can see that product code "201" applies to Invoice # "1", "3" and "4". When selecting field "A1" eq "201", you would only see invoices where fields 11, 12, 13 or 14 contains product code "201".
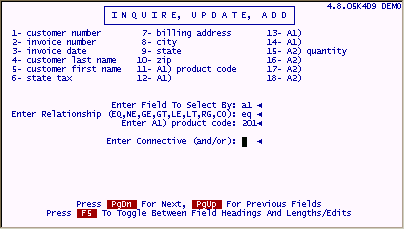
Results of "A1" eq "201"
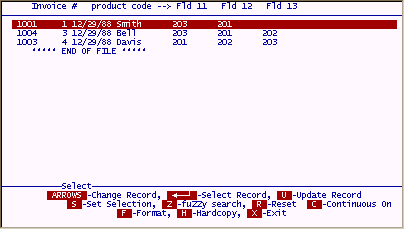
To get the same results without associated fields would require a more advanced search as follows;
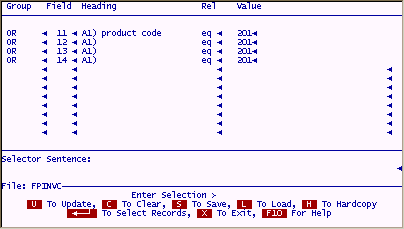
The above selection is not extensive for a group of four fields, but if it were 10 fields, you can see how time consuming creating the selection could be.
Sorting
Another big advantage of associated fields is sorting. We can now sort on the entire group of fields as a single group. The following example shows a typical sort.
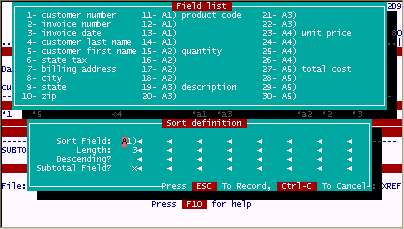
The results of sorting the file by "Customer number" and then "product code".
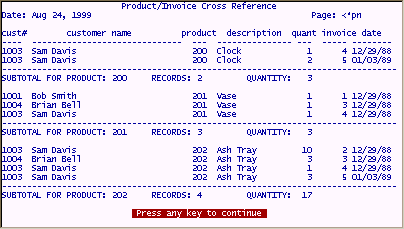
Without the associated field "A1" to sort on, it would very difficult to even get these results since the product code fields 11, 12, 13, 14 could only be sorted using four sort levels i.e. 1st, 2nd, 3rd, 4th sort respectively.
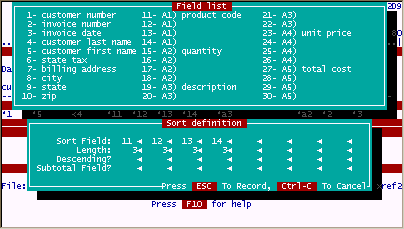
Product code "200" would only be sorted to the top of the list for all records only if it is entered into field 11 and never entered in fields 12, 13 or 14. If product code "200" was entered into any other field than field 11, it would show up further down the list after all product codes were sorted for field 11 as depicted in the following example.
Results of sorting by fields 11, 12, 13, 14
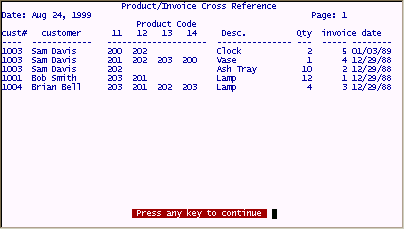
Notice that the description, quantity, and date fields relate only to the first associated field (field 11) on the above report and product codes seem to be in random order even they though they are sorted on the individual fields. The above report is not very useful and actually misrepresents the data.
Other Uses include calculating values
Associated fields are also valuable for calculating values. You can obtain a total_cost in a processing table by multiplying an associated field for quantity x unit cost.
@wlfA4): Total_cost = A2) * A4)
where: A2) = quantity; A4) = unit cost
This offers a great advantage in processing since you only need one line of programming code to calculate all associated subfields.
NOTE: You can have up to 32 instances of any subfield.
Non-filePro Files
With filePro, you can maintain data from other programs. The differences between filePro and non-filePro files are:
System maintained fields like @CD (creation date), @CB (created by), etc. are not available for Non-filePro files.
New records are only added to the end of the non-filePro file. Therefore, you can not overwrite deleted records. This will leave spaces in the non-filePro file that you may have to periodically scrub to keep the files as small as possible. After selecting the "Non-filePro file" option from define files, you will see the following screen.

Enter the full path (up to 58 characters) of your non-filePro data file and include the extension of the file if appropriate.
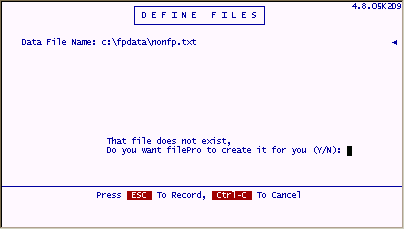
If the file does not exist, your will be prompted to create the empty file. At this point, there is no difference between defining a new non-filePro and filePro file.
You are limited to using ASCII type files with fixed record lengths. If you have existing alien file that you want to maintain using filePro, you will need to have a list of the files fields, field lengths, and know the record length. Keep in mind that special characters like CR/LF (carriage return/linefeed) have to be added to your file definition if these are used in the alien file.
Non-filePro File Utilities - filePro offers conversion utilities for some non-filePro file formats.
Click on Utilities.
General rules:
Respect the 8-character limit of WINDOWS if you want portability across platforms. The *nix limit is 14 characters, and WIN95/98/NT is 32 characters.
Wildcard-group your applications by name prefixes.
Example:
Nexapcd |
Nexapvd |
Nexarinv |
Nexapch |
Nexapvnd |
Nexarmenus |
Nexapmenus |
Nexarcd |
Nexarsls |
Nexaptd |
Nexarcus |
Nexartemp |
Nexaptemp |
Nexargs |
Nexctrl |
Nexarhst |
Nexenv |
Nexperms |
This way all of any wildcard group can be treated together, for example: The "ap" databases can be referred to at one time (nexap*), or all of the "ar" databases (nexar*)... ALL databases starting with "nex" can be moved to another system (nex*). This naming convention is not mandatory, it is only a helpful convention.
Qualifiers
Description:
Qualifiers allow you to develop and run the same application for up to 161 separate sets of data. For example, if you managed an accounting firm that performed payroll operations for other companies, you could develop a payroll program and use it on several separate sets of data. The separate sets of data would be qualified versions of the file. (It is possible to manipulate more than 161 sets of data, but that is the current limitation of the qualifier editor.)
With qualified files, there will be copies of the key segment, data segment and of each automatic index for every qualified version of the file.
Advantages
In this case, you want the data to remain totally separate. You never want to see data from company #1 together with company #2.
As far as the program is concerned, you only have one copy of the file definition, screens, formats, and processing tables. This will save you time in maintaining your systems since you will only have to make the change in one place on your system for all of your customers.
Offers additional flexibility and simplifies programming when dealing with large corporate systems.
Allows you to keep databases smaller and segregated thus improving performance and avoiding a complete (corporate) shutdown when a single divisions data becomes corrupted.
Creating Qualified Sets
Use "Define Files" and when asked to "Create Qualifiers (Y/N):" - Answer "Y".
The Edit Qualifiers table appears. Enter the specific qualifiers. The qualifier is a code to differentiate the separate sets of data.
Limits:
7 letters and/or numbers to a qualifier name (Unix and WIN95/98/NT)
3 letters and/or numbers (Windows)
Suppose you enter two qualifiers "act" and "bb", there will now be three separate sets of data, the unqualified version ("key") and two qualified versions ("keyaa" and "keybb").
Accessing Qualified Sets
To access the unqualified file use Inquire, Update, Add or Request Output as normal. To access either qualified file, use Inquire, Update, Add or Request Output with the following user menu flags:
?m code
uses the indicated file name qualifier
-md displays the "Enter File Name Qualifier" prompt after the
"Enter Pile Name" prompt
-mq "message" displays a user-defined prompt for the qualifier
Important Define Files Functions
"filePro & non-filePro files" |
All filePro files contain a hidden 20 byte header, Non-filePro files are structured ASCII files with no hidden header per record, therefore, no system maintained fields. |
Fields |
The real fields of any file. |
Data types & Edits |
Keep data clean and organized. |
Associated fields |
Unique feature of filePro. Group fields for searches and comparisons |
System Maintained Fields |
Record created by, creation date, updated by, updated date, etc. |
Qualifiers |
Unique to filePro and allowing multiple data sets with the same processing, screens and outputs. |
Password |
Security feature for locking the creation side of the menu on any file. |
Expert Level
Access Qualified Sets in Processing_tables
When defining processing, if you are standing in a qualified set of a file and do a lookup into a second file, the program will look for a qualified set of the same name in the second file. You can lookup data from a non-qualified set from a qualified set and vice-versa using the LOOKUP flags properly.
Make sure to use the LOOKUP filename@ when standing in a qualified set to access the non-qualified set. You also have the environment variable "PFQUAL" available to you, so this could be used to your advantage in conjunction with the "GETENV" command.
The "map" file
When you enter information in the "Define Files", filePro creates a definition layout called "map". If you look at the "map" for "FPCUST" with an editor, you will see something similar to the following;
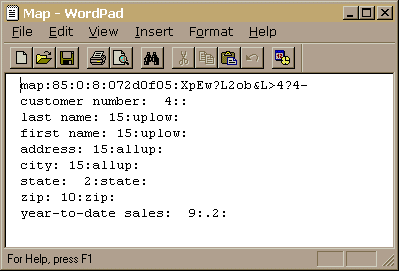
The first line of the map file is as follows;
Map:xxx:yyy:zzz:XXXXXXXX:PPPPPPPPPPPPPPP
Where:
Map is the literal "map".
xxx is the record length of the key (excluding the 20 byte header).
yyy is the record length of the data file.
XXXXXXXX is the 8 digit hexadecimal checksum of the encoded password.
PPPPPPPPPPPPPPPP is the encoded password.
The second and subsequent lines contain references to each field by name, length and data type. As you can see, the references are separated by a ":" colon.
Key Segment Description
The key segment record length shows how many characters will be contained on each record added to the file. There are another hidden 20 characters at the very beginning of every record. These are used by filePro for record housekeeping purposes. Some of these hidden bytes are used to keep track of when each record is created, who created it, when it was last updated, etc. These 20 hidden bytes are called the "header". A detail description of the key "Header" is as follows;
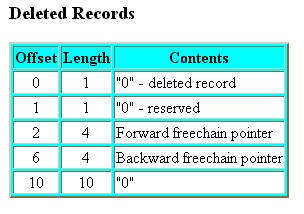
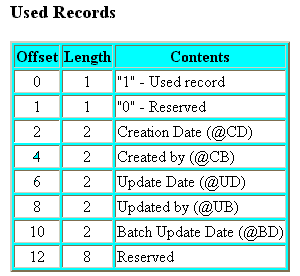
Dates are stored as the number of days since January 1, 1983.
User IDs are stored as the user ID number from the /etc/passwd file (UNIX/XENIX) or as "0" (Windows)
Password Keep in mind that a browse window will not display fields in the current file if the field is not included on the screen when the filePro file has a creation password.